Quá trình thu thập thông tin (Crawling) hay việc lập chỉ mục (Index) của website là những khái niệm phổ biến trong SEO. Là một marketer hay một người tìm hiểu về web chắc hẳn bạn đã nghe qua hai khái niệm này. Nhưng những gì chúng ta nghe được về thu thập thông tin hay lập chỉ mục là việc làm của Google.
Tuy nhiên hai khái niệm này, hoạt động như thế nào và chúng ảnh hưởng gì website của bạn hay không? Làm thế nào để Google nhận biết và lập chỉ mục cho website của bạn? Bạn đang muốn tìm đáp án cho những câu hỏi trên? Cùng EQVN tìm hiểu qua bài viết dưới đây nhé!
1. Thu thập thông tin (Crawling) là gì?
Thu thập thông tin (Crawling Data) là quá trình cho phép các công cụ tìm kiếm khám phá nội dung mới trên internet. Để làm được điều này, Google sẽ sử dụng các con bot thu thập thông tin theo các liên kết từ các trang web cũ đến các trang web mới.
Mỗi ngày sẽ có hàng nghìn trang web được sản xuất hoặc cập nhật nên quá trình này là một quá trình được lặp đi lặp lại mà không có hồi kết.

Martin Splitt – Nhà phân tích xu hướng của Google Search Console, ông mô tả quá trình thu thập thông tin như sau:
“ Trước tiên, chúng tôi sẽ duyệt toàn bộ qua Internet, và sẽ có những liên kết từ trang này đến trang khác. Khi chúng tôi bắt đầu ở đâu đó với một số URL, và sau đó về cơ bản theo các liên kết từ đó trở đi. Và chúng tôi đang thu thập thông tin theo cách của mình thông qua internet từng trang một, nhiều hơn hoặc có thể ít hơn. Sau khi tìm thấy những trang thông tin, chúng tin phải nắm được nội dung của trang đó đề cập đến phục vụ cho mục đích gì”
Thu thập thông tin là bước đầu tiên tiếp theo sẽ là lập chỉ mục (index), xếp hạng (các trang sẽ trải qua các thuật toán xếp hạng khác nhau ) và cuối cùng là xuất hiện trong kết quả tìm kiếm.
Hãy cùng EQVN tìm hiểu sâu hơn vấn đề cũng như xem cách thức hoạt động của thu thập thông tin.
2. Trình thu thập thông tin của công cụ tìm kiếm là gì?
Trình thu thập thông tin của công cụ tìm kiếm (còn được gọi là web spider hoặc crawl bot) là một phần của quá trình thu thập dữ liệu, quét nội dung trên các website và thu thập dữ liệu cho mục đích lập chỉ mục.
Bất cứ khi nào web spider truy cập vào một trang web mới thông qua siêu liên kết, nó sẽ xem xét nội dung trên trang web đó từ văn bản, yếu tố hình ảnh, liên kết, tệp HTML, CSS hoặc JavaScript, v.v. Và sau đó chuyển thông tin này để xử lý và lập chỉ mục cuối cùng.

2.1 – Trình thu thập thông tin của Google là gì?
Với tư cách là một công cụ tìm kiếm, Google sử dụng trình thu thập thông tin web của riêng nó có tên là Googlebot. Có 2 loại trình thu thập thông tin chính:
- Điện thoại thông minh Googlebot – trình thu thập thông tin chính
- Googlebot Desktop – trình thu thập thông tin thứ cấp
Googlebot thích thu thập dữ liệu các trang web chủ yếu dưới dạng trình duyệt trên điện thoại, nhưng nó cũng có thể thu thập lại mọi trang web bằng trình thu thập thông tin trên máy tính để kiểm tra cách trang web hiển thị thích ứng trên tất cả thiết bị.
Tần suất thu thập thông tin của các trang mới được xác định bởi ngân sách thu thập thông tin.
2.2 – Ngân sách thu thập thông tin là gì?
Ngân sách thu thập thông tin xác định số lượng và tần suất thu thập thông tin do trình thu thập thông tin thực hiện. Nói cách khác – nó quy định bao nhiêu trang sẽ được thu thập thông tin và tần suất các trang đó sẽ được Googlebot thu thập lại thông tin.

Ngân sách thu thập thông tin được xác định bởi 2 yếu tố chính:
- Giới hạn tốc độ thu thập thông tin – số lượng trang có thể được thu thập thông tin đồng thời trên trang web mà không làm quá tải máy chủ của nó.
- Thu thập thông tin theo nhu cầu – số lượng trang cần được Googlebot thu thập thông tin hoặc thu thập lại thông tin.
Ngân sách thu thập thông tin nên được chú trọng quan tâm đặc biệt là với các website lớn chứa hàng triệu webpages.
Nhưng có một ngân sách thu thập thông tin lớn có thể sẽ không mang lại bất kỳ lợi ích nào cho trang web vì nó không phải là tín hiệu về chất lượng cho các công cụ tìm kiếm.
3. Index (Lập chỉ mục) là gì?
Lập chỉ mục (Index) là một quá trình phân tích và lưu trữ nội dung từ các trang web đã được thu thập thông tin vào cơ sở dữ liệu (còn gọi là chỉ mục). Chỉ các trang được index mới có thể được xếp hạng và sử dụng trong các truy vấn tìm kiếm có liên quan.
Bất cứ khi nào web spider phát hiện ra một trang web mới, Googlebot sẽ chuyển nội dung của nó (ví dụ: văn bản, hình ảnh, video, thẻ meta, thuộc tính, v.v.) vào giai đoạn index nơi nội dung được phân tích rõ ràng cho phù hợp với từng ngữ cảnh và được lưu trữ trong mục lục.
Để làm điều này, Google sử dụng hệ thống lập chỉ mục Caffeine đã được giới thiệu vào năm 2010.
Cơ sở dữ liệu của chỉ mục Caffeine có thể lưu trữ hàng triệu triệu gigabyte. Các trang này được Googlebot xử lý và lập chỉ mục một cách có hệ thống theo từng nội dung.

Googlebot không chỉ truy cập các trang web bằng trình thu thập dữ liệu trên thiết bị di động trước mà còn thích lập chỉ mục nội dung có trên các phiên bản di động của họ kể từ bản cập nhật Mobile-First Indexing .
4. Index trên thiết bị di động là gì?
Tính năng ưu tiên lập chỉ mục trên thiết bị di động (mobile-first indexing) lần đầu tiên được giới thiệu vào năm 2016 khi Google thông báo rằng họ sẽ chủ yếu lập chỉ mục và sử dụng nội dung có sẵn trên phiên bản di động của website.
Tuyên bố chính thức của Google nói rõ:
“Trong lập chỉ mục ưu tiên thiết bị di động, chúng tôi sẽ chỉ lấy thông tin về trang web của bạn từ phiên bản dành cho thiết bị di động, vì vậy hãy đảm bảo Googlebot có thể xem toàn bộ nội dung và tất cả tài nguyên ở đó.”
Vì hầu hết mọi người sử dụng điện thoại di động, nên Google sẽ muốn xem xét các website ưu tiên cho trải nghiệm người dùng tốt. Đòi hỏi các chủ sở hữu trang web phải đảm bảo rằng website của họ đáp ứng và thân thiện với thiết bị di động (responsive và mobile-friendly).

Lưu ý: Điều quan trọng cần nhận ra là ưu tiên lập chỉ mục trên thiết bị di động không nhất thiết có nghĩa là Google sẽ không thu thập dữ liệu các trang web bằng tác nhân máy tính (Googlebot Desktop) để so sánh nội dung của cả hai phiên bản.
Bây giờ, chúng ta hãy xem xét các bước mà bạn có thể thực hiện khi thu thập thông tin hoặc lập chỉ mục trang web của mình.
5. Làm cách nào để Google thu thập dữ liệu và Index trang web của bạn?
Khi nói đến việc Crawling Data và Index thực tế không có “lệnh trực tiếp” nào khiến các công cụ tìm kiếm lập chỉ mục trang web của bạn.
Tuy nhiên, có một số cách gián tiếp khiến cho trang web của bạn sẽ được thu thập thông tin và lập chỉ mục.
5.1. Không làm gì – cách tiếp cận thụ động
Từ quan điểm kỹ thuật, bạn không phải làm bất cứ điều gì để trang web của bạn được Google Crawling Data và Index. Tất cả những gì bạn cần là một liên kết từ trang web bên ngoài và Googlebot cuối cùng sẽ bắt đầu thu thập thông tin và lập chỉ mục tất cả các trang có sẵn.
Tuy nhiên, việc thực hiện phương pháp “không làm gì cả” sẽ gây ra sự chậm trễ trong việc thu thập thông tin và lập chỉ mục. Nó sẽ có thể mất một khoảng thời gian để trình thu thập thông tin web phát hiện ra trang web của bạn.
5.2. Gửi các trang web qua công cụ kiểm tra URL
Một trong những cách bạn có thể thu thập dữ liệu và lập chỉ mục “an toàn” đối với các website riêng lẻ là trực tiếp yêu cầu Google Index (hoặc index lại) các trang của bạn. Bằng cách sử dụng Công cụ kiểm tra URL trong Google Search Console.
Công cụ này rất hữu ích khi bạn có một trang web mới hoặc bạn đã thực hiện một số thay đổi quan trọng đối với trang hiện có của mình và muốn lập chỉ mục nó càng sớm càng tốt.
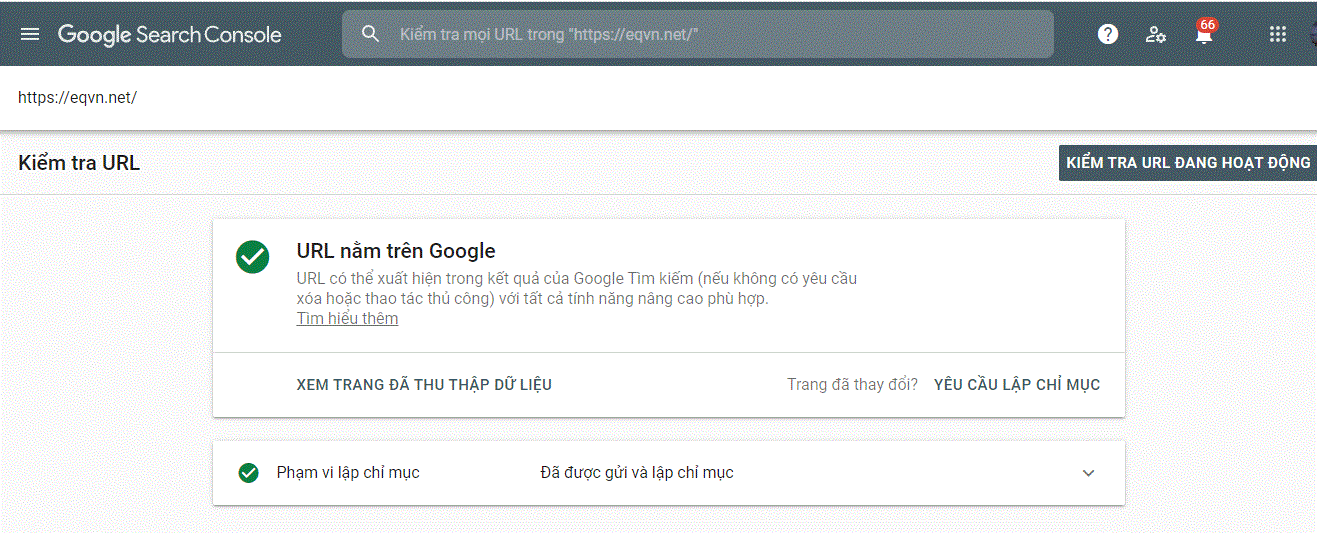
Quá trình này khá đơn giản:
- Truy cập Google Search Console và chèn URL của bạn vào thanh tìm kiếm ở trên cùng.
- Công cụ sẽ hiển thị cho bạn trạng thái của trang. Nếu nó chưa được lập chỉ mục, bạn có thể yêu cầu đến Google. Nếu đã được index, bạn không phải làm bất cứ điều gì hoặc yêu cầu lại (nếu bạn đã thực hiện bất kỳ thay đổi lớn hơn nào đối với trang).
- Công cụ kiểm tra URL sẽ bắt đầu kiểm tra xem phiên bản trực tiếp của URL có thể được lập chỉ mục hay không (có thể mất vài giây hoặc vài phút).
- Khi quá trình kiểm tra được thực hiện thành công, một thông báo sẽ bật lên, xác nhận rằng URL của bạn đã được thêm vào hàng đợi thu thập thông tin ưu tiên để lập chỉ mục. Quá trình index có thể mất từ vài phút đến vài ngày.
Lưu ý: Phương pháp lập chỉ mục này chỉ được khuyến nghị cho một số trang web. Không lạm dụng công cụ này nếu bạn muốn index một số lượng lớn các URL.
Yêu cầu lập chỉ mục không nhất thiết đảm bảo rằng URL của bạn sẽ được lập chỉ mục. Nếu URL bị chặn để thu thập thông tin hoặc lập chỉ mục hoặc có một số vấn đề về chất lượng mâu thuẫn với các nguyên tắc về chất lượng của Google, thì URL có thể hoàn toàn không được lập chỉ mục.
5.3. Gửi sơ đồ trang web
Sơ đồ trang web là một danh sách hoặc một tệp ở định dạng XML chứa tất cả các trang web của bạn.
Lợi ích chính của sơ đồ trang web là giúp công cụ tìm kiếm thu thập dữ liệu dễ dàng hơn nhiều. Bạn có thể gửi một số lượng lớn các URL cùng một lúc và tăng tốc quá trình lập chỉ mục tổng thể của trang web bạn.
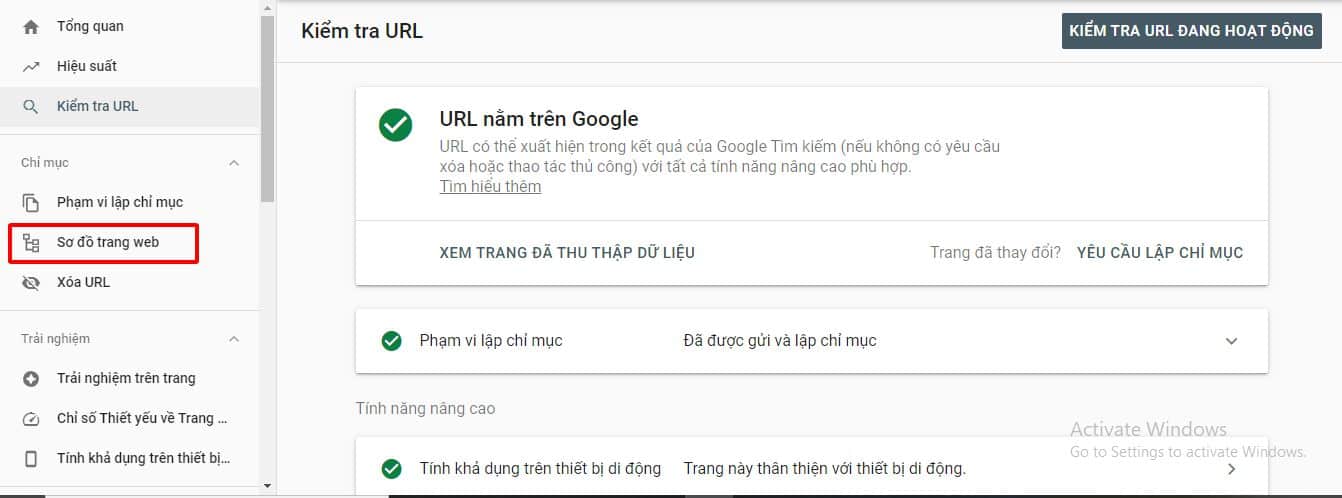
Để gửi sơ đồ trang web, bạn sẽ sử dụng Google Search Console.
- Cách dễ nhất để tạo sơ đồ cho trang web WordPress của bạn là sử dụng plugin Yoast SEO, nó sẽ tự động làm điều đó cho bạn.
- Sau đó, đi tới Google Search Console> Sơ đồ trang web và dán URL của sơ đồ trang web của bạn trong Thêm sơ đồ trang web mới
- Sau khi gửi, Googlebot cuối cùng sẽ kiểm tra sơ đồ trang web của bạn và thu thập dữ liệu mọi trang web được liệt kê mà bạn đã cung cấp.
5.4. Thực hiện liên kết nội bộ thích hợp
Một cấu trúc liên kết nội bộ mạnh mẽ là cách tiếp cận lâu dài và sẽ dễ dàng thu thập thông tin hơn.
Làm điều đó thế nào? Câu trả lời là một kiến trúc trang web phẳng (flat website architecture). Cấu trúc phẳng nghĩa là người dùng và trình công cụ tìm kiếm có thể truy cập vào bất cứ trang nào trên trang web của bạn trong 3 lần click chuột hoặc ít hơn.
Một trang web có kiến trúc liên kết tốt có thể bảo mật thu thập thông tin của tất cả các trang web mà bạn muốn được lập chỉ mục vì trình thu thập thông tin web sẽ dễ dàng truy cập vào tất cả chúng. Điều này đặc biệt quan trọng đối với các website lớn (ví dụ: thương mại điện tử) có hàng nghìn trang có sản phẩm.

Mẹo: Liên kết nội bộ là quan trọng nhưng bạn cũng nên nhắm đến việc nhận được các liên kết mạnh mẽ từ bên ngoài và website có thẩm quyền cao. Nó sẽ làm cho quá trình thu thập thông tin và lập chỉ mục được diễn ra thường xuyên cũng như xếp hạng cao hơn trong các SERP có liên quan.
6. Làm cách nào để ngăn Google thu thập dữ liệu và lập chỉ mục website?
Có nhiều lý do để ngăn Googlebot thu thập dữ liệu hoặc lập chỉ mục các phần trang web của bạn. Ví dụ:
- Nội dung riêng tư: thông tin của người dùng sẽ không xuất hiện trong kết quả tìm kiếm
- Các trang web trùng lặp: các trang có nội dung giống hệt nhau
- Các trang trống hoặc trang lỗi: các trang đang trong xây dựng và chưa chuẩn bị để được lập chỉ mục và hiển thị trong kết quả tìm kiếm
- Các trang có giá trị nhỏ: các trang do người dùng tạo không mang lại bất kỳ nội dung chất lượng nào cho các truy vấn tìm kiếm
Tại thời điểm này, rõ ràng là Googlebot rất hiệu quả khi phát hiện ra các trang web mới ngay cả khi bạn chưa có ý định lập chỉ mục hay thu thập dữ liệu.
Hãy xem xét các tùy chọn sau đây nếu như muốn ngăn chặn thu thập thông tin hoặc lập chỉ mục từ Google.
6.1. Sử dụng robots.txt (để ngăn thu thập thông tin)
Robots.txt là một tệp văn bản nhỏ chứa các lệnh trực tiếp cho trình thu thập thông tin web. Robots.txt giúp web spider biết nên hoặc không nên truy cập vào những URL nào trên trang web của bạn.
Bằng cách sử dụng lệnh “allow” và “disallow” trong tệp robots.txt, bạn có thể cho web spider biết những phần nào của trang web nên được truy cập và thu thập thông tin và những trang nào không nên.
Bất cứ khi nào web spider truy cập vào website của bạn, trước tiên sẽ kiểm tra xem website của bạn có chứa tệp robots.txt hay không và hướng dẫn dành cho chúng là gì. Sau khi đọc các lệnh từ tệp, chúng sẽ bắt đầu thu thập dữ liệu trang web của bạn theo hướng dẫn.
Nếu không có hướng dẫn từ tệp này, trình thu thập thông tin web sẽ truy cập mọi trang web mà nó có thể tìm thấy, bao gồm các URL mà bạn muốn tránh bị thu thập thông tin.

Mặc dù robots.txt có thể là một cách hay để ngăn Googlebot thu thập dữ liệu nhưng bạn cũng không nên dựa vào phương pháp này để ẩn nội dung nhé. Google vẫn có thể lập chỉ mục các trang web không được phép nếu một số trang web khác đang trỏ liên kết đến các URL này.
Để hiểu quả hơn bạn có thể thử phương pháp – Robots Meta Directives.
6.2. Sử dụng lệnh “noindex” (để ngăn Google Index)
Các lệnh meta rô-bốt (hoặc thẻ meta) là các đoạn mã HTML nhỏ được đặt trong phần <head> của trang web để hướng dẫn các công cụ tìm kiếm cách lập chỉ mục hoặc thu thập dữ liệu trang đó.
Một trong những lệnh phổ biến nhất là chỉ thị “noindex” (một lệnh meta rô bốt có giá trị noindex trong thuộc tính content ). Nó ngăn các công cụ tìm kiếm lập chỉ mục và hiển thị trang web của bạn trong SERPs.
Nó sẽ trông như thế này:

Thuộc tính “rô-bốt” có nghĩa là lệnh áp dụng cho tất cả các loại trình thu thập thông tin web.
Lệnh noindex đặc biệt hữu ích đối với các trang dành cho khách truy cập nhưng bạn không muốn chúng được lập chỉ mục hoặc xuất hiện trong kết quả tìm kiếm. Các noindex thường được kết hợp với “follow” hoặc “nofollow” thuộc tính để cho công cụ tìm kiếm biết rằng khi nào nên thu thập thông tin liên kết trên trang.
Quan trọng: Bạn không nên sử dụng cả chỉ thị noindex và tệp robots.txt để chặn trình thu thập thông tin web truy cập trang của bạn.
7. Làm thế nào để kiểm tra xem trang đã được Index hay chưa?
Để kiểm tra các trang web có được thu thập thông tin và lập chỉ mục hay không hoặc nếu một trang web cụ thể có một số vấn đề. Bạn hãy tham khảo có một số tùy chọn sau.
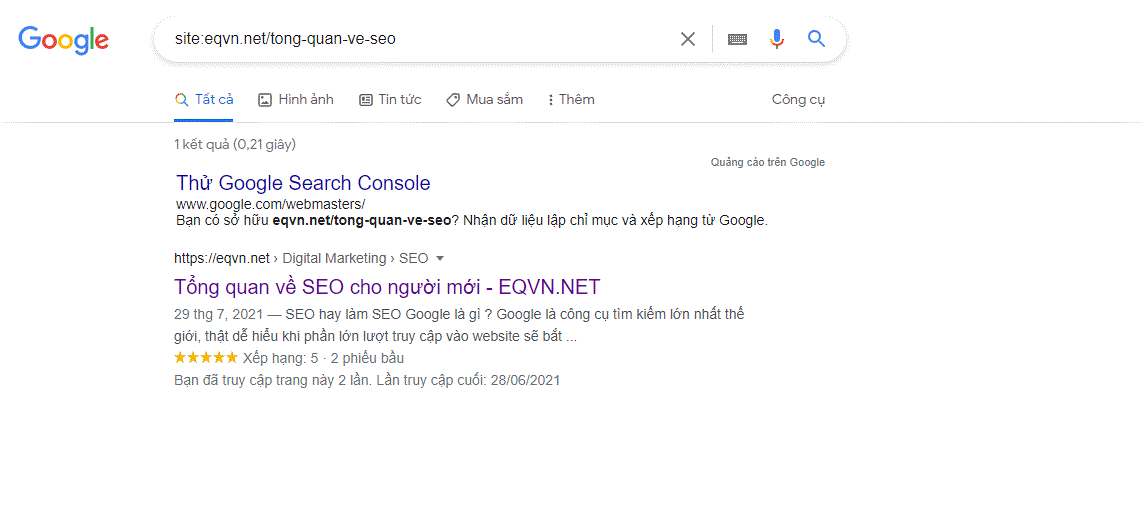
7.1. Kiểm tra thủ công
Cách đơn giản nhất để kiểm tra xem trang web của bạn được lập chỉ mục hay chưa là sử dụng site: domain
Nếu trang web của bạn đã được thu thập thông tin và lập chỉ mục. Bạn sẽ thấy tất cả các trang cũng như số lượng trang được lập chỉ mục trong phần “Giới thiệu về kết quả XY” . Nếu bạn muốn kiểm tra xem một URL cụ thể đã được index hay chưa, hãy sử dụng URL thay vì tên miền.
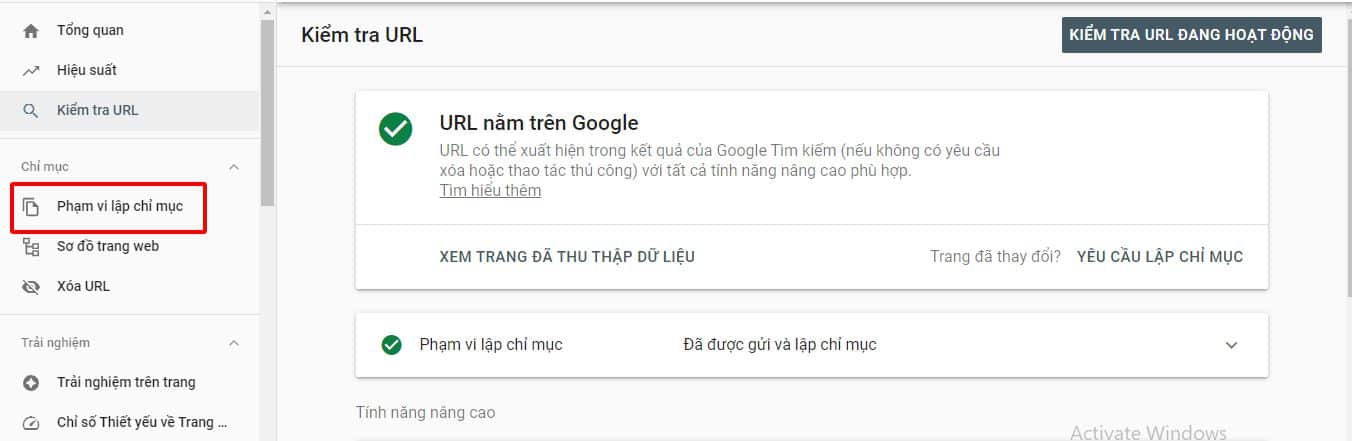
7.2. Kiểm tra trạng thái phạm vi chỉ mục
Để có cái nhìn tổng quan chi tiết hơn về các trang được lập chỉ mục. Bạn có thể sử dụng Báo cáo phạm vi lập chỉ mục trong Google Search Console.
Biểu đồ chi tiết trong Báo cáo phạm vi lập chỉ mục có thể cung cấp thông tin có giá trị về trạng thái của URL và các loại vấn đề với các trang được thu thập thông tin hoặc được lập chỉ mục.
7.3. Sử dụng công cụ Kiểm tra URL
Công cụ Kiểm tra URL có thể cung cấp thông tin về các trang web riêng lẻ trong website của bạn kể từ lần cuối cùng chúng được thu thập thông tin.
Bạn có thể kiểm tra xem trang web của mình có:
- Có lỗi hay vấn đề gì với chi tiết cụ thể về nguồn gốc của các lỗi này
- Có được thu thập thông tin hay chưa và lần thu thập thông tin gần đây nhất
- Trang đã được lập chỉ mục hay chưa và có thể xuất hiện trong kết quả tìm kiếm hay không
8. Kết luận
Qua bài viết này, chắc hẳn bạn đã có thể hiểu hơn và biết được một số cách để “tác động” đến Google để có thể index trang web nhanh hơn. Hoặc là ngăn chặn việc thu thập thông tin và lập chỉ mục từ Google. Và sử dụng một số cách để kiểm tra việc index của Google với trang web của bạn.
EQVN chúc bạn thành công với những thông tin bài viết mang đến!
Bài viết liên quan: